
机器翻译一直是人工智能研究领域的重头戏,自去年谷歌推出了神经机器翻译(GNMT)服务以来,相关技术的研发并没有止步不前,在多语言翻译和 zero-shot 翻译上也取得了引人注目的进展。近日,谷歌大脑和英伟达联合发布的一篇论文《序列到序列模型可以直接外语语音(Sequence-to-Sequence Models Can Directly Transcribe Foreign Speech)》将机器翻译这方面的研究又向前推进了一步,实现了从一种语言的语音到另一种语言的文本的直接端到端,而且其效果也要优于单独的语音模型和机器翻译模型的最佳结合。机器在本文中编译介绍了该研究的模型设计部分,更多内容请参考原论文。机器翻译一直是人工智能研究领域的重头戏,自去年谷歌推出了神经机器翻译(GNMT)服务以来,相关技术的研发并没有止步不前,在多语言翻译和 zero-shot 翻译上也取得了引人注目的进展。近日,谷歌大脑和英伟达联合发布的一篇论文《序列到序列模型可以直接外语语音(Sequence-to-Sequence Models Can Directly Transcribe Foreign Speech)》将机器翻译这方面的研究又向前推进了一步,实现了从一种语言的语音到另一种语言的文本的直接端到端,而且其效果也要优于单独的语音模型和机器翻译模型的最佳结合。机器在本文中编译介绍了该研究的模型设计部分,更多内容请参考原论文。

我们提出了一种循环编码器-解码器深度神经网络(recurrent encoder-decoder deep neural network)架构,该架构能将一种语言的语音直接转换为另一种语言的文本。模型并不会明确地将源语言语音转换为源语言文本,也不需要在训练过程中使用源语言的 ground truth 作为监督。我们在以前用于语音识别的带有注意架构(attention architecture)序列到序列(sequence-to-sequence)模型上进行了一些修改,并表明了其能处理这种更复杂的任务,了基于注意的模型的强大。一个端到端训练的单一模型在 Fisher Callhome 西班牙语-英语的语音翻译任务中达到了当前最高水平,在 Fisher 测试集上超过了一系列级联的单独训练的序列到序列语音识别和机器翻译模型 1.8 BLEU 分。另外,我们发现通过使用一个共享编码器网络来多任务训练序列到序列的语音翻译和识别模型,能让我们同时利用两种语言的训练数据,并能将表现进一步提升 1.4 BLEU 分。
我们使用了一种类似于 [1] 中所描述的带有注意架构的序列到序列模型。该模型由 3 个联合训练的神经网络构成:一个循环编码器,其可以将一个输入特征帧的序列 x1...T 转换成一个隐藏激活序列 h1...T,可以选择一个较慢的时间尺度:

这整个被编码的输入序列 h1...T 然后被一个解码器网络消费,并输出一个输出 token 的序列 y1...K,这是通过下一步预测完成的,即:根据之前的时间步骤所输出的 token 和整个编码的输入序列,在每一步输出一个输出 token(比如词或字符):
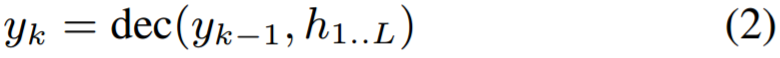
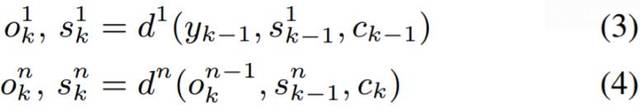
该解码器对输入的依赖是通过一个注意网络(attention network)来促成的,其可以将整个输入序列归纳为一个固定维度的语境向量 ck,该向量可使用跳过连接(skip connections)被传递给所有后续的层。在每一个输出步骤 k,ck 都从第一个解码器层开始计算:

其中 ae 和 ad 是小的全连接层。αkl 概率计算的是输入和输出序列之间的软对齐(soft alignment)。图 1 给出了一个例子。
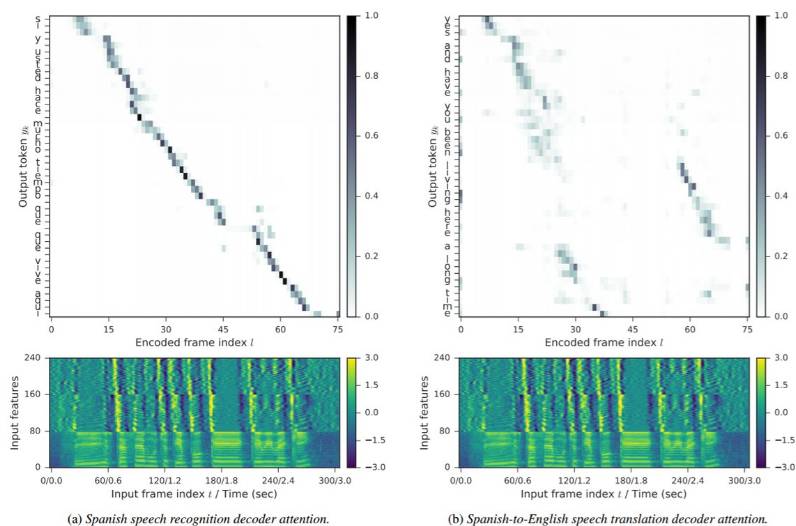
图 1:具有两个解码器的多任务模型的注意概率(attention probabilities)αkl 的案例。这个 ASR 注意基本上是单调的,而其翻译注意(translation attention)包含了序列到序列机器翻译模型通常具有的词重排序。首要注意帧 l = 58 ? 70,同时发出「living here」。该识别解码器注意到这些帧上,同时发出对应的西班牙短语「vive aqui」。ASR 解码器比翻译注意要更有置信度,并且也往往使得每个输出 token 的许多输入帧上更加平滑。这也是西班牙语语音和英语翻译之间模糊映射的结果。
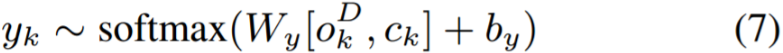
我们为端到端语音翻译和一个语音识别的基线seq 模型。我们发现来自 [10] 的一个变体的同样架构在两个任务上表现都很好。我们使用了 80 个通道的对数梅尔滤波器组特征(log mel filterbank features),其是从带有 10 ms 跳过(hop)大小的 25 ms 窗口提取出来的。所有模型的输出 softmax 会在 90 个符号中预测出其中一个,这些符号包括英语和西班牙语的小写字母。详见第 4 节。
编码器共有 8 层。输入特征的组织形式是 T × 80 × 3 的张量,即原始特征、deltas 和沿「深度(depth)」维度的 delta-delta 联结体(concatennation)。使用 ReLU 激活函数,它被传入到两个堆叠的卷积层,每个包含 32 个核(kernel),大小为 3 × 3 × 时间深度 × 频率。这两个层的步幅为 2 × 2,在时间序列上以 4 的总采样因子来对序列进行下采样,从而减少后续层中的计算。在每个层后会用到 Batch Normalization[24]。
使用一个 1×3 的滤波器,下菜样得到的特征序列然后被传入一个单层双向卷积 LSTM [25, 26, 10](也就是在每个时间步骤中只在频率维度上取卷积)。最后,它被传递到三层的双向 LSTM 堆栈中,其每个方向大小为 256,交错着 512 维的线性投射(linear projection),然后是 batch normalization 和 一个 ReLU 激活函数,来计算最后的 512 维编码器表征 hl。
解码器的输入由串级一个 yk-1 的 64 维嵌入、先前每个时间步骤发出的符号和 512 维的注意语境(attention context)向量 ck 所创造出的。ck 是使用 ae 和 ad 网络来计算的(查看公式 6),其中每个网络都包含一个带有 128 个单元的单隐层。这被传递到一个带有 4 个单向 LSTM 层(带有 256 个单位)堆栈中。最后,注意语境和 LSTM 输出的联结体(concatenation)被传递到一个 softmax 层,来预测在输出词汇中发出每个符号的概率。
该网络使用 TensorFlow [27] 实现,并且在具有 64 个表达方式的 minibatch 上使用了 teacher forcing 进行训练。我们使用参数 β1 = 0.9、β2 = 0.999 和的 Adam 优化器 [28] 进行使用 10 个副本的异步随机梯度下降。初始学习率设置为 0.001,并在 100 万步之后以 10 的系数衰减。L2 的权重使用 1e-6 权重衰减,并从 20k 步开始,将标准差为 0.125 的高斯加权噪点添加入所有 LSTM 层和解码器嵌入的权重中。然后调整超参数以最大化在 Fisher/dev 集上的表现。
我们使用在 8 个假设模型和集束宽度为 3 上进行排序修剪的集束搜索进行解码,并使用在 [7] 中提出的评分函数。我们并没有使用任何语言模型。对于基线 ASR 模型(baseline ASR model),我们发现既不需要长度归一化,也不需要 [7] 提出的覆盖罚项(coverage penalty)。然而,只有当它的对数概率(log-probability)比下一个最可能的 token 还要大三倍时,才允许发送序列结束 token。对于语音翻译我们发现长度归一化为 0.6 的时候,性能会提高 0.6 BLEU 分。
我们还参照 [7] 训练了一个基线seq 文本机器翻译模型。为了减少在小训练语料库上的过拟合,我们相对于 [7] 而显著减小了模型的大小。
其编码器网络由 4 个编码器层(共 5 个 LSTM 层)组成。正如在基础架构中的一样,其底层(bottom layer)是一个双向 LSTM 而其余的层都是单向的。其解码器网络由 4 个堆叠的 LSTM 层构成。所有的编码器和解码器 LSTM 层都包含 512 个单元。我们为输入和输出使用了和上述语音模型发出的一样的字符级的词汇。
如 [7] 中的一样,我们在训练过程中应用了概率为 0.2 的 dropout [29] 来减少过拟合。我们使用了带有一个单个副本的 S 进行训练。使用了 128 个句子对的 minibatch,训练在大约 100k 步之后实现了。
我们通过一种多任务配置 [30] 对语音识别模型和翻译模型进行了联合训练,并使用了源语言副本的监督。我们使用了上述的模型和训练协议,其中每一个工作器(worker)都会在每一步选择一个随机的任务来进行优化。我们还进行了以下修改:我们使用了 16 个异步的工作器、在 30k 的整体步骤引入了权重噪声(weight noise)、在 150 万整体步骤之后对学习率进行了衰减。
推荐:


网友评论 ()条 查看